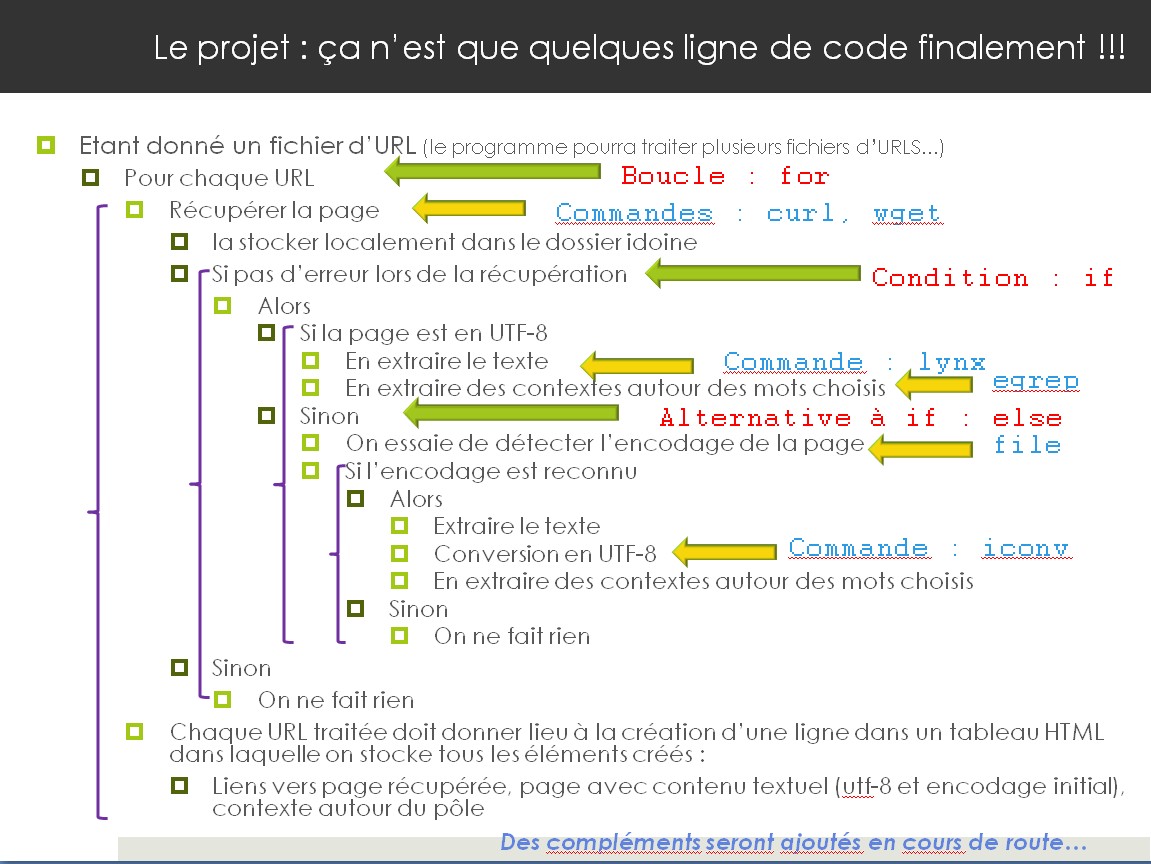
Quand nous lançons notre script pour créer un tableau contenant les adresses URLS, les pages aspirées, les DUMPs initiaux et les DUMPs en UFT-8, un message d'erreur de ce type s'affiche parfois dans le terminal :
iconv: (stdin):8:8: cannot convert
Cela signifie que bien qu'on ait indiqué à la commande iconv des encodages apparenant à sa bibliothèque, certains caractères posent encore problème au moment de la conversion !
Nous avons cherché à savoir quelle était l'origine de ce problème et comment il pouvait être résolu dans notre chaîne de traitement...
Voici une capture d'écran du message d'erreur dans le terminal au moment où nous lançons le script4 (fichier disponible dans un précédent) :
Et voici maintenant les images des fichiers produits à partir de cette URL qui pose problème :
Le code source de la page aspirée :
Le fichier DUMP initial :
Le fichier DUMP converti en UTF-8 :
On peut déduire en comparant le fichier DUMP initial et le fichier DUMP en UTF-8 que c'est le caractère É (é majuscule) qui pose problème. La commande iconv interrompt la conversion du DUMP initial en UTF-8 au moment où elle rencontre ce caractère. On se retrouve alors avec un fichier DUMP en UTF-8 incomplet !
Mais comment se fait-il que iconv ne puisse pas convertir le caractère É en UTF-8 ? Pour comprendre cela il faut comparer le code source de la page HTML aspirée et le DUMP intial.
Dans le code source HTML, ce caractère est codé au moyen de l'entité de caractère É que Lynx interprète correctement comme É et qu'on retrouve donc ensuite tel quel dans le fichier
DUMP :
extrait du code html :

résultat dans le DUMP :

Cela a pour principale conséquence que la commande
file identifie l'encodage de la page aspirée comme étant en ASCII (puisque tous les caractères accentués qui s'affichent dans le navigateur sont eux même codés au moyen de caractères ASCII selon le prinicpe des entités de caractère). Lynx étant lui même un navigateur, les entités de caractère sont remplacés dans le fichier DUMP obtenu par les caractères correspondants. L'encodage du fichier DUMP ne peut donc pas être en ASCII s'il contient des caractères accentués.
Or voici dans notre script les différentes étapes que nous suivons pour convertir le DUMP initial en UTF-8 :
- On capture la page web avec la commande
curl
- On utilise la commande
file sur la page aspirée pour détecter son encodage
- Si l'encodage identifié par la commande
file n'est pas en UTF-8, alors on cherche si cet encodage appartient à la bibliothèque de
iconv
- Si c'est la cas, on dump la page aspirée avec Lynx et on converti ce dump en UTF-8 en indiquant dans les options de la commande
iconv l'encodage de départ (=celui de la page web aspirée) et l'encodage de sortie (UTF-8).
Cette procédure ne peut donc plus fonctionner correctement dans le cas qu'on vient de présenter puisque l'encodage identifié par la commande
file pour la page aspirée ne correspond pas à celui du DUMP. Pour que la commande
iconv fonctionne correctement, il faudrait donc plutôt lui indiquer l'encodage du fichier DUMP au lieu de donner celui de la page aspirée.
Pour cela, nous allons donc devoir revoir notre chaîne de traitement en créant le fichier DUMP plus tôt...
Voici ce que nous proposons dans le cas où la commande
file identifie un encodage de la page aspirée différent de UTF-8 :
- on crée le fichier DUMP de la page aspirée
- on détecte l'encodage du fichier DUMP grâce à la commande
file ($encodageDump)
- si l'encodage détecté appartient à la bibliothèque de
iconv, on convertit le fichier DUMP en UTF-8 et on crée une nouvelle ligne dans le tableau contenant les liens vers l'adresse URL, le fichier HTML aspiré, le fichier DUMP initial et le fichier DUMP en UTF-8. Pour bien se repérer, on indique aussi dans le tableau l'encodage détecté par la commande
file pour la page aspirée et le DUMP. (Pour ça, on utilise deux variables :
$encodage et
$encodageDump)
- si l'encodage détecté au moyen de la commande
file n'appartient pas à la bibliothèque de
iconv, on cherche au moyen de la commande
egrep un encodage dans les balises HTML de la page aspirée
- si on trouve un encodage et qu'il appartient à la liste des encodages disponibles avec
iconv alors on crée une nouvelle ligne dans le tableau. On pourrait avoir à cette étape des erreurs avec
iconv si l'encodage récupérer dans la balise
<meta> ne correspond pas tout à fait à l'encodage réél du document html, mais on laisse tomber ce cas pour l'instant !
- si aucun encodage n'est reconnu, on créé quand-même une nouvelle ligne dans le tableau avec le fichier DUMP initial, mais on ajoute la mention "(encodage inconnu)" et on ne lance aucune convertion en UTF-8.
Voici une capture d'écran de la partie que nous avons modifié dans notre script :
Et voici les résultats :
- plus de message d'erreur dans le terminal :
- le fichier DUMP-UTF-8 qui posait problème est maintenant complet et tous les caractères s'affichent correctement :
- les tableaux produits sur un test avec quelques URLs seulement :
On voit bien dans le tableau 1 les différents encodages reconnus par la commande
file dans le cas où un web master à utiliser des entités de caractère...






































{kind=link}